関係データベースについて
関係データベースとは
関係データベース(Relational Database:RDB)とは
関係データベースとは、関係モデルにもとづいて設計・開発されたデータベースのことです。
簡単にいえば、行と列から構成される2次元の表で表現されるデータベースのことです。
知名度のあるRDB製品としては、Oracle Database、Microsoft SQL Server、MySQL、PostgreSQL、DB2などがあります。
関係モデルとは
関係モデルとは、1970年にIBM社のエドガー・F・コッド氏が提唱した、データの集合を数学的に表現したモデルです。
このモデルでは、データ群を複数項目の「関係」(relation)として捉えます。
| 関係モデルの概念 | 説明 | RDBの対応機能 |
|---|---|---|
| 関係(relation) | データを表形式で表したもの。 | 表・テーブル |
| タプル(tuple) | 複数の属性を管理するデータ構造。関係内の1行を指す。 | 行(レコード) |
| 属性(attribute) | データの特性を定義する。 | 列(カラム) |
| 定義域(domain) | 特定の属性が取りうるすべての値の集合を指す。 | データ型(文字列型、整数型など) |
キーについて
主キー(primary key)とは
主キーとは、データベース内のテーブルにおいて、行(レコード)を一意に識別するために使用される列(カラム)のことです。
主キーには以下の2つの条件(主キー制約)があります。
・一意性制約(ユニーク制約):その列の中に重複するデータがあってはならない。
・非ナル制約:その列の中にNULLがあってはならない。
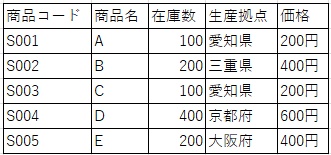
例えば、以下のテーブルにおいて、主キーは「商品コード」になります。
商品コードさえ分かれば、その商品の名前や在庫数など諸々の情報を取得することが可能となるからです。
スーパーキー(super key)と候補キー(candidate key)について
スーパーキーとは、レコードを一意に識別するための属性またはその組み合わせのことです。
簡単にいえば、行を特定できるできるならば、どんな組み合わせで作っても良いキーのことです。
ですので、その組み合わせパターンは多数あり、上図のテーブルにおいては「{商品コード}、{商品コード, 生産拠点}、{商品名, 生産拠点}」などがスーパーキーになります。
候補キーとは、テーブル内から行(レコード)を一意に識別することができる項目(列)の組み合わせのことです。
つまり、主キーの候補となるキーが候補キーであり、候補キーの中から「主キー」が選ばれます。
なお、候補キーは、次の2つの性質を持つ必要があります。
・一意性:行を一意に識別できること。
・極小性:必要最小限の属性の集合
上図のテーブルにおいて、「商品コード」と「商品名」は候補キーになります。
商品名を一意な名前として定義するならば、商品名は主キーとして扱うことが可能です。
しかし、例えば生産拠点によって同じ製品名でも製品コードを変えるならば商品名は重複されてしまうため、主キーに設定することはできません。
主キーを選定する場合、「スーパーキー」の中から「候補キー」を取り出し、そこから「主キー」を選定することが一般的です。
外部キー(foreign key)とは
外部キーとは、他のテーブルの主キーを参照する属性のことです。
外部キーとなる属性のデータは必ず参照先の列に存在している必要があります。

その他のキー
| キーの種類 | 説明 |
|---|---|
| 複合キー |
複数の属性を組み合わせて構成された主キーのこと。 複合キーが本当に一意になっているかは設計に依存し、設計ミスがあれば運用エラーとなります。 |
| 代理キー(alternate key) | 候補キーの中から主キーに選ばれなかったキーのこと。 |
| 自然キー(natural key) |
入力された値を、主キーとして使うキーのこと。 入力が一意であることを保証する前提がある。 |
| 代用キー(surrogate key) |
システム側が自動採番した値を主キーとして使うキーのこと。 |
関係演算について
関係演算(relational operation)とは
関係演算とは、関係データベースの表から目的のデータを取り出す演算のことです。
関係演算は、3種類あります。
| 演算 | 説明 |
|---|---|
| 射影(projection) | 表の中から特定の列を抽出する。 |
| 選択(selection) | 表の中から条件に合致した行を抽出する。 |
| 結合(join) | 二つ以上の表を結合して、一つの表を生成する。 |
結合演算とは
結合演算とは、結合するための演算のことです。
「=」や「<」などの演算子を使い、条件設定をします。
なお、結合のために用いられるキーを結合キーと呼びます。
正規化について
正規化とは
正規化とは、データの重複をなくして、データの整合性を確保するようにデータベースを設計することです。
正規化することで、データ不整合やデータ喪失を防ぎ、メンテナンス性やパフォーマンスを高めることができます。
正規化の段階は、一般的には第1~第3正規形までとなります。
この他にも、第1~第5正規形、ボイスコッド正規形(3.5正規形)、ドメインキー正規化などがあります。
非正規形
非正規形とは、正規化が全く行われておらず、1行の中に複数の繰り返し項目が存在する状態です。
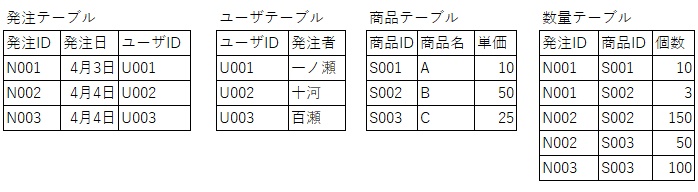
第一正規化
第一正規化では、繰り返し項目を排除します。
簡単にいえば、列を一意になるように整理して、1つのセルに1つの値しか含まれない状態にします。
第二正規化
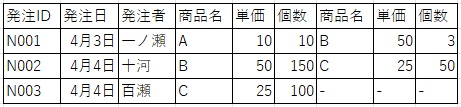
第二正規化では、「部分関数従属」している列を排除します。
簡単にいえば、テーブルの中に主キーが複数混在しているため、これを解消するという作業になります。
・関数従属とは、Xの値が決まればYの値が決まる関係(X→Y)のことです。
・部分関数従属とは、複合キーの一部の項目だけで、列の値が一意に定まる関係のことです。
つまり、複合キーの内、一部のキーは不要であり、データが冗長になっているということです。
第二正規形は、部分関数従属している列を切り離し別のテーブルとして整理します。
これは、縦方向の重複を無くす作業です。
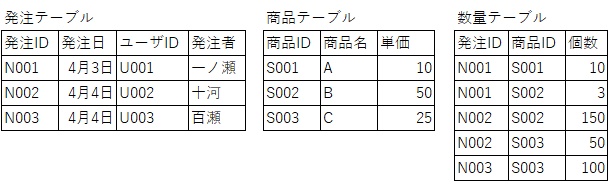
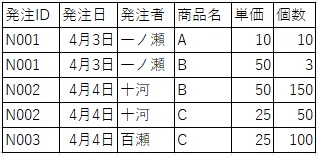
第三正規化
第三正規化では、「推移的関数従属」している列を排除します。
簡単にいえば、更に分離できる部分を分離する作業になります。
・推移的関数従属とは、関数従属が推移的に成立する関係のことです。
「Aが決まるとBが決まって、Bが決まるとCが決まる」という関係です。
第三正規化では、外部キーを用いてデータを切り分け、別のテーブルに切り出します。
下図では、ユーザ情報は一か所にまとめられますので、ユーザテーブルを作成してそこで管理します。
これにより、変更があったときに修正する箇所を減らし、データベースの一貫性を確保することができます。
また、中心的な役割になっている数量テーブルは「発注明細書テーブル」という名前に変えたほうがいいかもしれません